One of the crucial business dimensions is the dimension “Where”. It is necessary to know where a customer was born or where he lives. Where will the order be delivered? Where have there been more sales, and where can we sell more? Where are our stores located? From Where is the customer accessing our e-commerce? These and other principal questions use the “Where” dimension. Today the best service to provide geographic accuracy and quality for these data is Google Maps.
In an earlier article (hope, you’ve read it), we took a look at the CircleCI deployment system, which integrates perfectly with GitHub. Why then would we want to look any further? Well, GitHub has its own CI/CD platform called GitHub Actions, which is worth exploring. With GitHub Actions, you don’t need to rely on some external, albeit cool, service.
In this article we’re going to try using GitHub Actions to deploy the server part of InterSystems Package Manager, ZPM-registry, on Google Kubernetes Engine (GKE).
I have a need to dynamically create a web application definition in a namespace using ObjectScript. I am having trouble finding a cache class or routine that let's me do this.
As I am writing this article, Bitcoin costs less than one-fifth of what it used to be at the pinnacle of its success. So when I start telling someone about my blockchain experience, the first thing I hear is undisguised skepticism: "who needs this blockchain stuff now anyway?"
That's right, the blockchain hype has waned. However, the technologies it is based on are here to stay and will continue being used in particular areas.The Internet in general offer tons of materials describing the general usage of these technologies
I've this warning message in SMP (attached below), we have more than enough disk space (1.5TB free) so not sure where to check and what could be the problem, eg. which database, global or process ...etc?
Sounds odd - but I encountered it - twice now. Cache was restarted. in that period the primary journal directory was full and it was writing to the secondary journal directory. So upon start-up, it was quite obvious that it was not going to write to the primary. Cache reported this but was able to continue with the start-up but writing to the secondary. All of a sudden it doesn't recognize the 'primary' config any more and started saying 'Alternate and primary journal directories are the same'.
(We are in contact with IS support for this problem but I would like to ask Community too, perhaps somebody experienced this problem in the past)
Hello Community,
we need your help with Cache 2017.2 freezing on Linux machine.
Since we moved our primary production Cache from Windows to Linux in the begging of this year, we have experienced system freezing twice. Yesterday without any good reason Cache stopped to respond with the log shown below.
I need to convert a JSON payload to a custom object type. Currently, I'm converting the JSON object to a %Library.DynamicObject object and need to proceed from here.
As of now, these are my options
1. Using an external library talked about in this link:
I am looking to run some analysis on existing software to quickly identify global variable references. Ideally you would feed in a "starting routine" and after going through all referenced routines you would end up with a finite set of global variables. So the primary purpose is to take say 10,000 lines of code and map out the referenced global structures without relying on a programmers eye. I found the post on Object Script equivalent to Studio "Find in Files" interesting but the downside is that output is too verbose and would require parsing to extract the global structures. How would you override writing to the terminal so that you could parse the data?
For a solo developer developing web applications what will be the best technology to use IRIS or Studio with cache database and containers for deployment
Hi all - I'm running a Zen page that inherits from %Zen.Component.page, and I'd like to step through code and debug it. Is this possible, and how?
I've tried to attach to a process that I think is mine (it has my internal IP address) but is using "Unknown User". Any ideas on where to start debugging the page -- this page calls lots of other pages. I'd thought I'd start at the home page.
Perhaps I need to navigate to my page that I want to debug, and attach at that point.
Any info on the debugger in this atypical use is appreciated.
This code snippet allows for a file on the web to be saved into the file system. Specify the server and GET request, as well as the directory the file should be saved to. The class method "test" runs the code:
Class objectscript.saveFileHTTP Extends %RegisteredObject
{
classmethod test() {
Set httprequest = ##class(%Net.HttpRequest).%New()
Set httprequest.Server = "docs.intersystems.com"
Do httprequest.Get("documentation/cache/20172/pdfs/GJSON.pdf")
Do $System.OBJ.Dump(httprequest.HttpResponse)
Set stream=##class(%FileBinaryStream).%New()
Set stream.Filename="c:\test.pdf"
Write stream.CopyFrom(httprequest.HttpResponse.Data)
Write stream.%Save()
}
}
I'm working with an EnsLib.XML.X12.Document object which consists of a parent object along with multiple children.
When using the following code, my sent object is losing all references to its children. I've played with the deep parameter and nothing is working to automatically clone the objects children(group docs ref)along with itself. (Even though the documentation states that it should..)
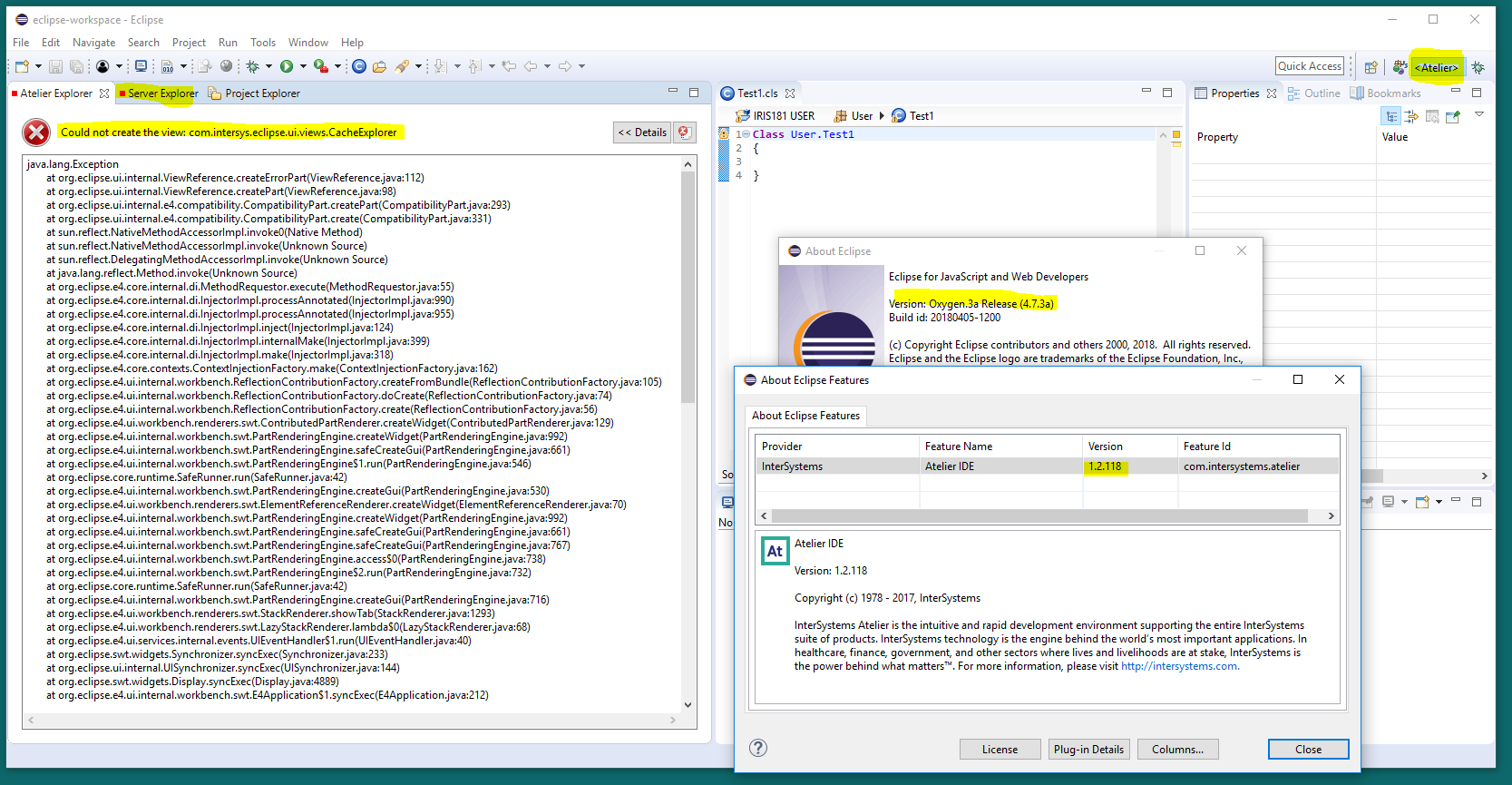
The Eclipse environment persists perspective data to enable layout customization and other features. Sometimes when this data becomes out of date, Eclipse fails to clear references to it. For example, upgrading a plug-in can leave behind data about an earlier version of that plug-in. This mechanism applies to all Eclipse plug-ins and is not unique to the Atelier plug-in.
In light of this: You may find that after upgrading from Atelier 1.1 to 1.2, your Atelier perspective looks something like:
Let me share with you a minimal embedded python template, that I can recommend as a starting point for any general project with InterSystems IRIS that will use embedded python.
Features:
Embedded Python ready;
Examples of 3 ways of Embedded python development;
Currently, we are utilizing batch jobs at the OS level to kick off routines that watch for files. We are trying to convert these processes to be performed by the Task Manager.
The routines have while loops and perform while loops so long as the time parameters are being met.
What's the best way to ensure Task Manager kicks them off after the completion of the shutdown/backup/start process is performed, which we do nightly? I want to ensure that it starts it regardless of the time that we've set.
 All time
All time Open Exchange app
Open Exchange app

.png)