Loading your IRIS Data to your Google Cloud Big Query Data Warehouse and keeping it current can be a hassle with bulky Commercial Third Party Off The Shelf ETL platforms, but made dead simple using the iris2bq utility.
Let's say IRIS is contributing to workload for a Hospital system, routing DICOM images, ingesting HL7 messages, posting FHIR resources, or pushing CCDA's to next provider in a transition of care. Natively, IRIS persists these objects in various stages of the pipeline via the nature of the business processes and anything you included along the way. Lets send that up to Google Big Query to augment and compliment the rest of our Data Warehouse data and ETL (Extract Transform Load) or ELT (Extract Load Transform) to our hearts desire.
A reference architecture diagram may be worth a thousand words, but 3 bullet points may work out a little bit better:
It exports the data from IRIS into DataFrames
It saves them into GCS as .avro to keep the schema along the data: this will avoid to specify/create the BigQuery table schema beforehands.
It starts BigQuery jobs to import those .avro into the respective BigQuery tables you specify.
AnalyzeThis is a tool for getting a personalized preview of your own data inside of InterSystems BI. This allows you to get first hand experience with InterSystems BI and understand the power and value it can bring to your organization. In addition to getting a personalized preview of InterSystems BI through an import of a CSV file with your data, Classes and SQL Queries are now supported as Data Sources in v1.1.0!
For many in today's interoperability landscape, REST reigns supreme. With the overabundance of tools and approaches to REST API development, what tools do you choose and what do you need to plan for before writing any code?
This article focuses on design patterns and considerations that allow you to build highly robust, adaptive, and consistent REST APIs. Viable approaches to challenges of CORS support and authentication management will be discussed, along with various tips and tricks and best tools for all stages of REST API development. Learn about the open-source REST APIs available for InterSystems IRIS Data Platform and how they tackle the challenge of ever-increasing API complexity.
The article is a write-up for a recent webinar on the same topic.
Does anyone NOT use a debugger? I can't remember the last time I did. It's not because I don't dislike them, I just don't need to use them. The main reason for this is because I have a certain development methodology that either produces less bugs, catches them at a unit test level, or makes tracking them down much easier.
ObjectScript has at least three ways of handling errors (status codes, exceptions, SQLCODE, etc.). Most of the system code uses statuses but exceptions are easier to handle for a number of reasons. Working with legacy code you spend some time translating between the different techniques. I use these snippets a lot for reference. Hopefully they're useful to others as well.
I am an avid user of ZEN for over 10 years now and it works for me. But it seems that Intersystems are no longer actively developing it (or ZEN Mojo), the only published reference to this is here
Database systems have very specific backup requirements that in enterprise deployments require forethought and planning. For database systems, the operational goal of a backup solution is to create a copy of the data in a state that is equivalent to when application is shut down gracefully. Application consistent backups meet these requirements and Caché provides a set of APIs that facilitate the integration with external solutions to achieve this level of backup consistency.
A few years ago, I was teaching the basics of our %UnitTest framework during Caché Foundations class (now called Developing Using InterSystems Objects and SQL). A student asked if it was possible to collect performance statistics while running unit tests. A few weeks later, I added some additional code to the %UnitTest examples to answer this question. I’m finally sharing it on the Community.
This week I am going to look at CPU, one of the primary hardware food groups :) A customer asked me to advise on the following scenario; Their production servers are approaching end of life and its time for a hardware refresh. They are also thinking of consolidating servers by virtualising and want to right-size capacity either bare-metal or virtualized. Today we will look at CPU, in later posts I will explain the approach for right-sizing other key food groups - memory and IO.
This post is dedicated to the task of monitoring a Caché instance using SNMP. Some users of Caché are probably doing it already in some way or another. Monitoring via SNMP has been supported by the standard Caché package for a long time now, but not all the necessary parameters are available “out of the box”. For example, it would be nice to monitor the number of CSP sessions, get detailed information about the use of the license, particular KPI’s of the system being used and such. After reading this article, you will know how to add your parameters to Caché monitoring using SNMP.
If you’ve ever wondered whether there is a way to regulate access to resources in Caché, wonder no more. In version 2014.2 special classes were added that allow developers to work with semaphores.
The newer dynamic SQL classes (%SQL.Statement and %StatementResult) perform better than %ResultSet, but I did not adopt them for some time because I had learned how to use %ResultSet. Finally, I made a cheat sheet, which I find useful when writing new code or rewriting old code. I thought other people might find it useful.
First, here is a somewhat more verbose adaptation of my cheat sheet:
I was first introduced to TDD almost 9 year ago, and I immediately fell in love with it. Nowadays it's become very popular but, unfortunately, I see that many companies don't use it. Moreover, many developers don't even know what it is exactly or how to use it, mainly beginners.
As a developer, you have probably spent at least some time writing repetetive code. You may have even found yourself wishing you could generate the code programmatically. If this sounds familiar, this article is for you!
We'll start with an example. Note: the following examples use the %DynamicObject interface, which requires Caché 2016.2 or later. If you are unfamiliar with this class, check out the documentation here: Using JSON in Caché. It's really cool!
For each defined property, query or an index, several corresponding methods would be automatically generated on a class compilation. These methods can be very useful. In this article, I would describe some of them.
This series of articles would cover Python Gateway for InterSystems Data Platforms. Leverage modern AI/ML tools and execute Python code and more from InterSystems IRIS. This project brings you the power of Python right into your InterSystems IRIS environment:
Just like Caché pattern matching, Regular Expressions can be used in Caché to identify patterns in text data – only with a much higher expressive power. This article provides a brief introduction into Regular Expressions and what you can do with it in Caché. The information provided herein is based on various sources, most notably the book “Mastering Regular Expressions” by Jeffrey Friedl and of course the Caché online documentation. The article is not intended to discuss all the possibilities and details of regular expressions. Please refer to the information sources listed in chapter 5 if you would like to learn more. If you prefer to read off-line you can also download the PDF version of this article.
I' have done some tests with Caché and Apache Zeppelin. I want to share my experince to use both systems together. I'll try to describe all steps that are required to config Zeppelin to connect to Caché.
Hi all. Today we are going to upload a ML model into IRIS Manager and test it.
Note: I have done the following on Ubuntu 18.04, Apache Zeppelin 0.8.0, Python 3.6.5.
Introduction
These days many available different tools for Data Mining enable you to develop predictive models and analyze the data you have with unprecedented ease. InterSystems IRIS Data Platform provide a stable foundation for your big data and fast data applications, providing interoperability with modern DataMining tools.
The last time that I created a playground for experimenting with machine learning using Apache Spark and an InterSystems data platform, see Machine Learning with Spark and Caché, I installed and configured everything directly on my laptop: Caché, Python, Apache Spark, Java, some Hadoop libraries, to name a few. It required some effort, but eventually it worked.
Have some free text fields in your application that you wish you could search efficiently? Tried using some methods before but found out that they just cannot match the performance needs of your customers? Do I have one weird trick that will solve all your problems? Don’t you already know!? All I do is bring great solutions to your performance pitfalls!
As usual, if you want the TL;DR (too long; didn’t read) version, skip to the end. Just know you are hurting my feelings.
I needed to know programmatically if last ran failed or not.
After some exploring, here's the code:
ClassMethod isLastTestOk() As %Boolean
{
set in = ##class(%UnitTest.Result.TestInstance).%OpenId(^UnitTest.Result)
for i=1:1:in.TestSuites.Count() {
#dim suite As %UnitTest.Result.TestSuite
set suite = in.TestSuites.GetAt(i)
return:suite.Status=0 $$$NO
}
quit $$$YES
}
I am planning to implement Business Intelligence based on the data in my instances. What is the best way to set up my databases and environment to use DeepSee?
InterSystems Data Platform includes utilities and tools for system monitoring and alerting, however System Administrators new to solutions built on the InterSystems Data Platform (a.k.a Caché) need to know where to start and what to configure.
This guide shows the path to a minimum monitoring and alerting solution using references from online documentation and developer community posts to show you how to enable and configure the following;
Caché Monitor: Scans the console log and sends emails alerts.
System Monitor: Monitors system status and resources, generating notifications (alerts and warnings) based on fixed parameters and also tracks overall system health.
Health Monitor: Samples key system and user-defined metrics and compares them to user-configurable parameters and established normal values, generating notifications when samples exceed applicable or learned thresholds.
History Monitor: Maintains a historical database of performance and system usage metrics.
pButtons: Operating system and Caché metrics collection scheduled daily.
Remember this guide is a minimum configuration, the included tools are flexible and extensible so more functionality is available when needed. This guide skips through the documentation to get you up and going. You will need to dive deeper into the documentation to get the most out of the monitoring tools, in the meantime, think of this as a set of cheat sheets to get up and running.
In this series of articles, I'd like to present and discuss several possible approaches toward software development with InterSystems technologies and GitLab. I will cover such topics as:
Git 101
Git flow (development process)
GitLab installation
GitLab Workflow
Continuous Delivery
GitLab installation and configuration
GitLab CI/CD
In the previous article, we covered Git basics, why a high-level understanding of Git concepts is important for modern software development, and how Git can be used to develop software. Still, our focus was on the implementation part of software development, but this part presents:
GitLab Workflow - a complete software life cycle process - from idea to user feedback
Continuous Delivery - software engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time. It aims at building, testing, and releasing software faster and more frequently.
 By update
By update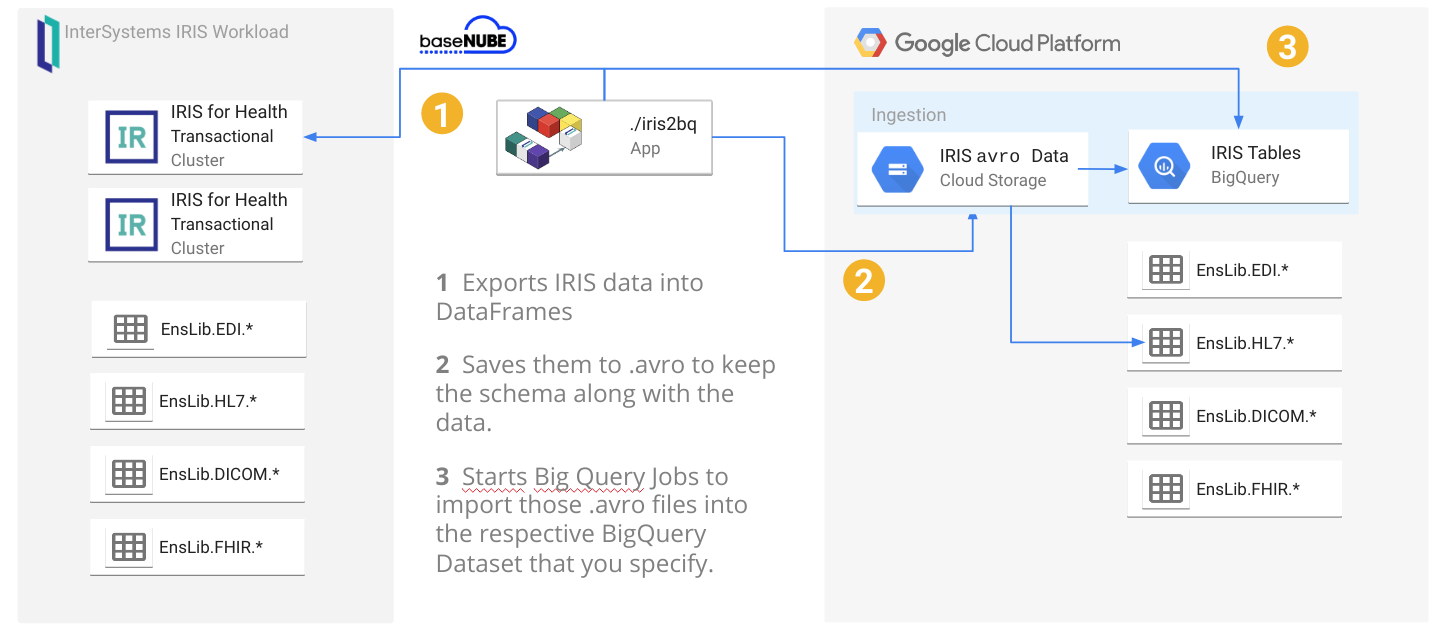
 Open Exchange app
Open Exchange app